Titanic - Machine Learning from Disaster
This is my first Kaggle work where I have published my prediction and have improved my accuracy for the Titanic - Machine Learning from Disaster.
I had followed many notebooks and tutorials for creating this notebook.
The Work
After a lot of studying and references to a lot of notebooks, I finally was able to understand this notebook. It is using a LogisticRegression model to obtain the prediction.
The interesting things that I gathered from this notebook are that it had custom functions to get all the missing data and also many graphs to illustrate the missing data in both the training and the test datasets.
Also, it is using a method to factorize the data for normalization and filling out the NaN's as -999 for Age and Fare. There was a detailed report taken with the use of the pandas_profiling library.
With this as a base, I started my analysis.
To improve the score from 0.77511 all I had to do was the following alterations:
- Fill better mean values for the Age and Fare missing values instead of -999
- Remove unwanted columns
Fill better mean values
Filling mean median and mode values to NaN missing values will improve the model efficiency to a better amount in my case from 0.77511 to 0.77990.
First I had taken the Correlation between the features as I had to group them on the basis of other correlated features so that I can get mean and fill in the missing values.
Filling Missing Values
Fare
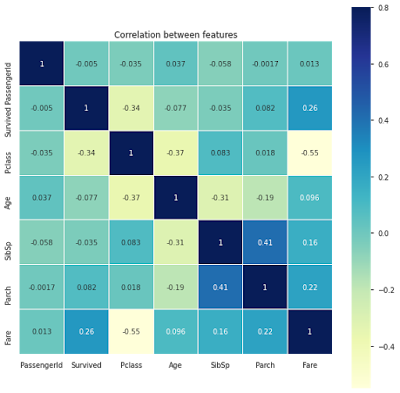 |
| Fig 1: Correlation Matrix between the features |
 |
| Fig 2: Missing Values in the training dataset |
 |
| Fig 3: Missing Values in the test dataset |
Age
For Age, I had the idea to extract the salutation from the name and group them together and aggregate the mean Age, and fillup the values based on that. Even then I found out that 'Ms' salutation was missing the age field in the test data. For this, I again ran through the same grouping aggregate through the Sex attribute.
Remove unwanted columns
 |
| Fig 4: Dropped Columns |
I never knew removing data had an impact on the model accuracy. After a lot of searching in the Kaggle forums, tutorials, and peer help (Swati Damele), I found that we have to remove unnecessary columns from the data that I had created for the Salutation. Removing this improved the model significantly from a score of 0.7790 to 0.78947
Future work to be done...
 |
| Fig 5: Box plot showing the outliers |
There are more things that can be done to improve the score like Removing outliers that I have found and recorded in the Age, SibSp, Parch, and Fare.
To Avoid
 |
| Fig 6: Removing outliers |
Must not use 25th quantile and 75th quantile to remove outliers. It decreased my accuracy from 0.78947 to 0.76315.
Conclusion
Wrapping things up, the following were the observations:
- Fill better mean values.
- Remove unwanted columns.
Bibliography
Wholehearted thanks for helping me achieve this:
- Swati Damele
- https://www.kaggle.com/mishraay/titanic-dataset-prediction-easily-understandable
- https://www.kaggle.com/mskbr1/titanic-project-kernel
- https://www.kaggle.com/saisivasriram/titanic-feature-understanding-from-plots



Comments
Post a Comment